
When building a machine learning model, the types of data used can vary widely. One approach to handling this variety
Continue reading
When building a machine learning model, the types of data used can vary widely. One approach to handling this variety
Continue reading
Modern AI models rely heavily on large volumes of data for accurate predictions and performance. However, loading and preprocessing large
Continue reading
현대의 인공지능(AI) 모델은 정확한 예측과 성능을 위해 대용량의 빅 데이터로 학습하는 것이 중요하다. 그러나 대용량 데이터를 불러오고 전처리하는 데는 상당한
Continue reading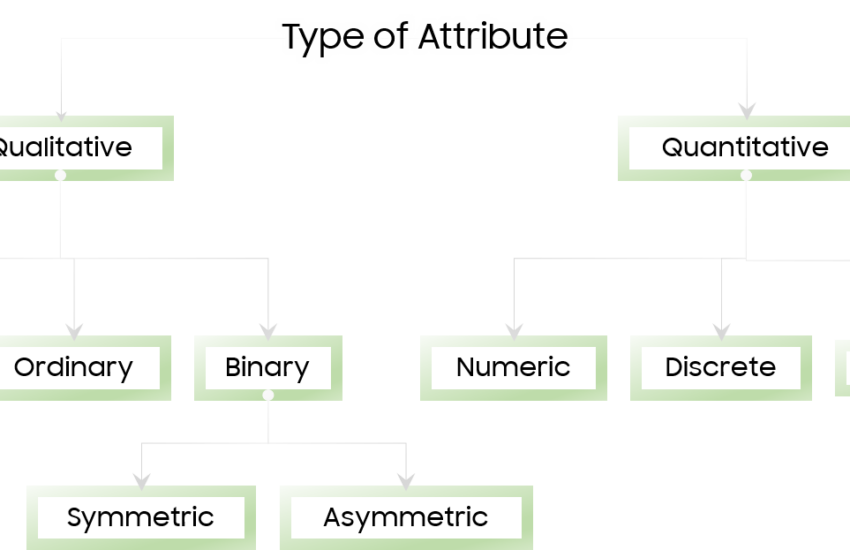
Dataset A dataset is composed of data objects, and a data object represents an entity(a concept or unit of meaningful
Continue reading
What is Data Mining? Data mining is the process of discovering useful correlations hidden among vast amounts of data, extracting
Continue reading
“이상치(Outlier)”란 데이터 세트에서 다른 관찰값들과 크게 다른 값을 가진 관찰 결과를 말한다. 이상치는 데이터 수집, 측정 오류 또는 실제 변동성으로
Continue reading
‘결측치(Missing Data)‘란 데이터 세트에서 관찰되지 않거나 기록되지 않은 값들을 의미한다. 다양한 이유로 데이터 수집 과정에서 일부 정보가 누락되거나, 기록되지 않아
Continue reading
데이터가 정규 분포를 따른다는 가정은 데이터 사이언스와 통계학에서 매우 중요한 역할을 하며, 정규 분포의 이해는 분석의 정확도와 신뢰성을 높이는 데
Continue reading
일반적인 데이터 정규화 방법 최소-최대 정규화(Min-Max Normalization) Z-점수 정규화(Z-Score Normalization) 로버스트 정규화(Robust Scaling) 정규화 방법에 따른 차이를 차트로 확인하기 데이터
Continue reading
탐색적 데이터 분석(Exploratory Data Analysis, EDA)이란 데이터를 분석하기 전에 데이터의 주요 특성을 이해하고, 데이터에 숨겨진 패턴, 이상치, 구조 등을 탐색하는
Continue reading