
최근 AI 기반 언어 모델은 텍스트 생성과 이해, 자연어 처리 분야에서 놀라운 성과를 이루고 있다. OpenAI의 ChatGPT는 이러한 모델 중
Continue reading
최근 AI 기반 언어 모델은 텍스트 생성과 이해, 자연어 처리 분야에서 놀라운 성과를 이루고 있다. OpenAI의 ChatGPT는 이러한 모델 중
Continue reading
OpenAI가 개발한 인공지능(AI) 언어 모델인 ChatGPT의 개발 히스토리와 버전별 차이점에 대해 좀 더 알아보고자 한다. 1. GPT의 개발 히스토리GPT 모델은
Continue reading
Chat GPT는? ChatGPT는 OpenAI에서 개발한 대규모 언어 모델 중 하나이다. GPT는 “Generative Pre-trained Transformer”의 약자로, 이 모델은 대규모 텍스트 데이터를
Continue reading
데이터세트 분할은 머신 러닝 모델을 학습시키기 위한 중요한 단계 중 하나이다. 머신러닝 모델 학습에 있어서 데이터세트를 학습용(train), 검증용(validation), 테스트용(test)으로 나누는
Continue reading
유의수준(Level of Significance) 가설검증에서 귀무가설이 실제로 참일 때 귀무가설에 대한 판단의 오류수준(잘못 기각할 확률)을 말하며, 제1종 오류※의 위험성을 부담할 최대 확률을
Continue reading
기술 성숙도 기술 성숙도 평가는 개발 기술의 성숙도 또는 이행단계를 평가하기 위한 정량화된 측정지표로, 연구 개발 환경(실험실, 유사환경, 실제환경), 연구개발
Continue reading
모델을 구축하거나 모형을 학습하고 평가 하기 위해서 Dataset이 필요하다.이때 Dataset은 성질에 맞게 3가지로 분류하여 사용한다. Dataset이 충분히 커서 Train을 위해
Continue reading
정형 데이터(Structured Data) 란?정형 데이터는 구조화된 데이터라고도 말하며 표준화된 형식이고, 구조가 잘 정의되어 있으며, 데이터 모델을 준수하고, 지속적인 순서를 따르고,
Continue reading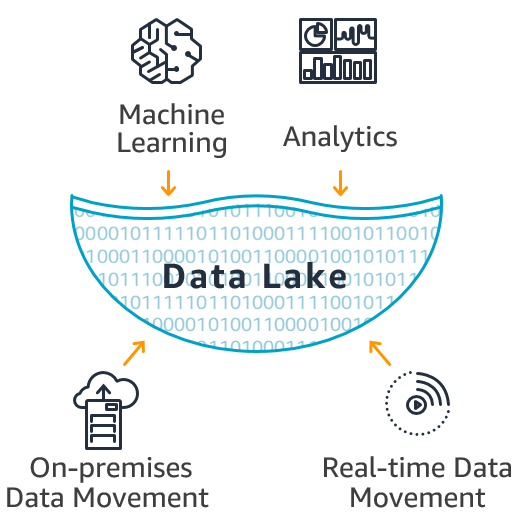
데이터 레이크란? 데이터 레이크(Data Lake)는 대량의 데이터를 생성되는 원시 형식으로 보관하는 중앙 위치를 말한다.기존의 계층적 데이터 웨어하우스(파일이나, 폴더에 저장하는)와 다르게
Continue reading
불확실성과 우연 현상을 다루는 확률은 논리적이고 결정론 적이며 인과 관계가 뚜렷한 다른 수학 주제와 확연히 구별되는 특성을 지닌다. 그런 연유에서
Continue reading