
모집단 (Population) 표본 (Sample) 차이점 이러한 차이점을 이해하는 것은 데이터를 해석하고, 연구 결과를 일반화하는 방법을 결정하는 데 중요하며, 데이터 사이언스에서
Continue reading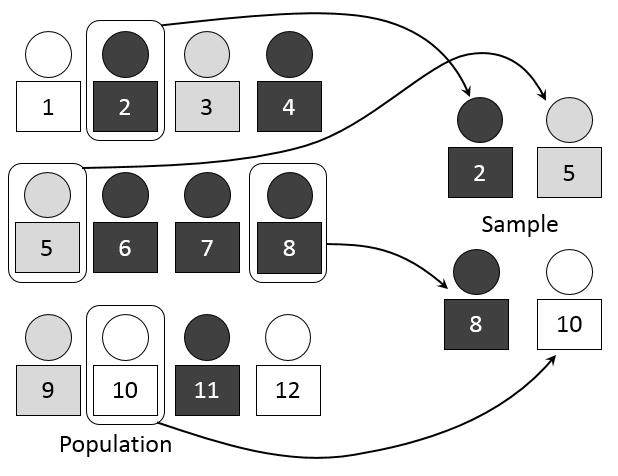
모집단 (Population) 표본 (Sample) 차이점 이러한 차이점을 이해하는 것은 데이터를 해석하고, 연구 결과를 일반화하는 방법을 결정하는 데 중요하며, 데이터 사이언스에서
Continue reading
분산 (Variance) 표준편차 (Standard Deviation) 분산과 표준편차는 데이터의 변동성 또는 흩어진 정도를 수치적으로 나타내는 중요한 통계적 측정 도구이다. 분산은 데이터의
Continue reading
평균 (Mean) 중앙값 (Median) 모드 (Mode) 이 세 가지 측정치는 데이터의 중심 경향성을 파악하는 데 있어 서로 다른 측면을 제공한다.
Continue reading
데이터 보강(Data Augmentation) 이란? 기존 데이터 세트를 변형하여 새로운 데이터를 생성하는 기술로 실질적인 데이터 세트의 규모를 키울 수 있는 방법이다.이를
Continue reading
산업 현장에서는 다양한 생산설비와 제어시스템을 통해 대량의 데이터를 생성하고 관리한다. 이러한 데이터는 최적화된 생산 과정, 품질 향상, 예측 정비 등
Continue reading
정형 데이터 적재 정형 데이터란 구조화된 데이터로, 일정한 형식을 갖추고 있는 데이터를 말하며, 이러한 데이터를 적재(Loading)하기 위해서는 여러가지 방법들이 있지만,
Continue reading
Mixed Data Learning은 다양한 유형의 데이터를 사용하여 학습하는 기술이다. 이러한 데이터는 텍스트, 이미지, 오디오, 비디오 등 여러 형식일 수 있다.
Continue reading
데이터세트 분할은 머신 러닝 모델을 학습시키기 위한 중요한 단계 중 하나이다. 머신러닝 모델 학습에 있어서 데이터세트를 학습용(train), 검증용(validation), 테스트용(test)으로 나누는
Continue reading
유의수준(Level of Significance) 가설검증에서 귀무가설이 실제로 참일 때 귀무가설에 대한 판단의 오류수준(잘못 기각할 확률)을 말하며, 제1종 오류※의 위험성을 부담할 최대 확률을
Continue reading
이번에는 미국 초등학교의 Type 비교를 해보고자 한다.학교 Type은 Public, Private으로 구분되며, 데이터를 수집한 Great Schools은 학교와 교육에 대한 정보를 제공하는
Continue reading