
Streamlit은 Python을 사용하여 데이터 기반 웹 애플리케이션을 쉽고 빠르게 개발할 수 있는 오픈 소스 라이브러리이다. 데이터 사이언티스트와 머신러닝 엔지니어들이 데이터
Continue reading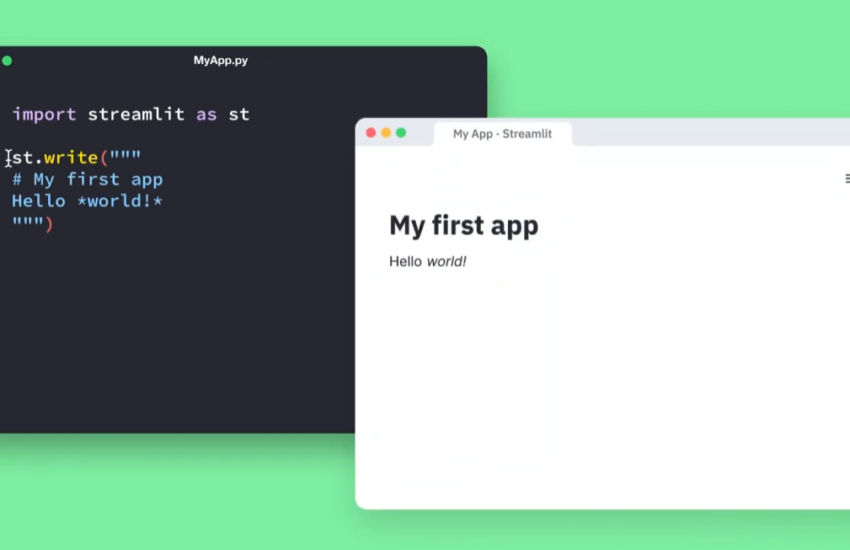
Streamlit은 Python을 사용하여 데이터 기반 웹 애플리케이션을 쉽고 빠르게 개발할 수 있는 오픈 소스 라이브러리이다. 데이터 사이언티스트와 머신러닝 엔지니어들이 데이터
Continue reading
Modern AI models rely heavily on large volumes of data for accurate predictions and performance. However, loading and preprocessing large
Continue reading
현대의 인공지능(AI) 모델은 정확한 예측과 성능을 위해 대용량의 빅 데이터로 학습하는 것이 중요하다. 그러나 대용량 데이터를 불러오고 전처리하는 데는 상당한
Continue reading
In industrial settings, most of the data is initially unstructured. Converting this data into structured format and storing it in
Continue reading
시계열 분석의 주요 영역 중 하나는 이동 평균 모델(Moving Average Model, MA)이다. 이 포스트에서는 MA 모델의 기본 원리와 이를 데이터
Continue reading
데이터가 정규 분포를 따른다는 가정은 데이터 사이언스와 통계학에서 매우 중요한 역할을 하며, 정규 분포의 이해는 분석의 정확도와 신뢰성을 높이는 데
Continue reading
오늘은 데이터 분석에서 자주 사용되는 두 가지 회귀 방법, 선형 회귀와 로지스틱 회귀에 대해 알아볼 예정이다. 이 두 방법은 비슷한
Continue reading
일반적인 데이터 정규화 방법 최소-최대 정규화(Min-Max Normalization) Z-점수 정규화(Z-Score Normalization) 로버스트 정규화(Robust Scaling) 정규화 방법에 따른 차이를 차트로 확인하기 데이터
Continue reading
모수적 방법 (Parametric Methods)이란? 모수적 방법은 모집단이 특정 분포(대개 정규 분포)를 따른다고 가정하는 통계적 분석 방법이다. 이러한 방법은 분포의 특정
Continue reading
제1종 오류 (Type I Error) 제2종 오류 (Type II Error) 차이점 이 두 오류 사이의 균형을 맞추는 것은 통계적 분석에서
Continue reading