
ChatGPT Pro는 OpenAI가 새롭게 선보인 프리미엄 서비스로, 연구자, 개발자, 데이터 과학자 등 전문 사용자들을 위해 설계된 고급 인공지능 모델을 제공하는
Continue reading
ChatGPT Pro는 OpenAI가 새롭게 선보인 프리미엄 서비스로, 연구자, 개발자, 데이터 과학자 등 전문 사용자들을 위해 설계된 고급 인공지능 모델을 제공하는
Continue reading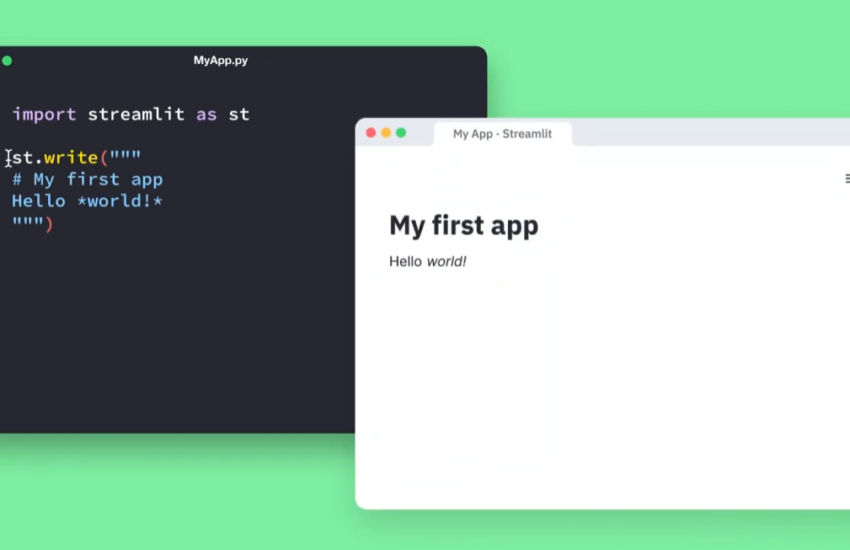
Streamlit은 데이터를 기반으로 한 애플리케이션 개발에 적합하며, 외부 API와의 통합은 Streamlit의 활용도를 한층 높여준다. 이번 포스트에서는 외부 API를 Streamlit과 연동하여
Continue reading
실시간 데이터 시각화는 데이터 분석 애플리케이션에서 매우 유용한 기능이다.Streamlit을 사용하면 Python 기반으로 손쉽게 실시간 대시보드를 구축할 수 있다.이번 글에서는 Streamlit으로
Continue reading
Streamlit은 Python을 사용하여 데이터 기반 웹 애플리케이션을 쉽고 빠르게 개발할 수 있는 오픈 소스 라이브러리이다. 데이터 사이언티스트와 머신러닝 엔지니어들이 데이터
Continue reading
데이터 과학과 머신러닝에서 고차원 데이터는 매우 일반적이다. 하지만 고차원 데이터를 분석하고 시각화하는 것은 쉽지 않다. 이를 해결하기 위해 t-SNE(t-Distributed Stochastic
Continue reading
데이터 과학과 머신러닝에서는 고차원의 데이터가 문제 해결의 중요한 요소이다. 그러나 차원이 클수록 계산 비용이 증가하고, 과적합(overfitting)의 위험이 커질 수 있다.
Continue reading
다익스트라 알고리즘(Dijkstra’s Algorithm)은 가중치가 있는 그래프에서 최단 경로를 찾는 가장 널리 사용되는 알고리즘 중 하나이다. 이 알고리즘은 네트워크 라우팅, 지도
Continue reading
머신러닝 모델을 구축할 때, 사용되는 데이터의 유형은 매우 다양할 수 있다. 이 중 하나의 접근법이 바로 “Mixed Data Learning”이다. 이
Continue reading
Jupyter Notebook과 Jupyter Lab은 데이터 사이언티스트와 개발자에게 필수적인 도구이다.이들 환경에서는 단축키를 사용하여 생산성을 더욱 극대화할 수 있으므로, 단축키를 정리하여 공유
Continue reading
현대의 인공지능(AI) 모델은 정확한 예측과 성능을 위해 대용량의 빅 데이터로 학습하는 것이 중요하다. 그러나 대용량 데이터를 불러오고 전처리하는 데는 상당한
Continue reading