
Streamlit은 Python을 사용하여 데이터 기반 웹 애플리케이션을 쉽고 빠르게 개발할 수 있는 오픈 소스 라이브러리이다. 데이터 사이언티스트와 머신러닝 엔지니어들이 데이터
Continue reading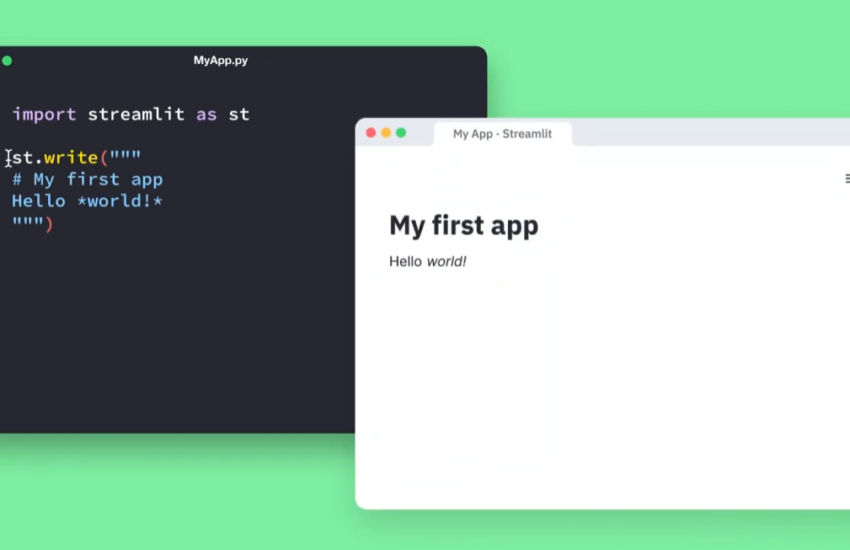
Streamlit은 Python을 사용하여 데이터 기반 웹 애플리케이션을 쉽고 빠르게 개발할 수 있는 오픈 소스 라이브러리이다. 데이터 사이언티스트와 머신러닝 엔지니어들이 데이터
Continue reading
데이터 과학과 머신러닝에서 고차원 데이터는 매우 일반적이다. 하지만 고차원 데이터를 분석하고 시각화하는 것은 쉽지 않다. 이를 해결하기 위해 t-SNE(t-Distributed Stochastic
Continue reading
데이터 과학과 머신러닝에서 차원 축소는 분석 및 모델링의 성능을 높이기 위해 매우 중요한 과정이다. 그 중 선형 판별 분석(LDA, Linear
Continue reading
데이터 과학과 머신러닝에서는 고차원의 데이터가 문제 해결의 중요한 요소이다. 그러나 차원이 클수록 계산 비용이 증가하고, 과적합(overfitting)의 위험이 커질 수 있다.
Continue reading
데이터 사이언스에서는 종종 매우 큰 데이터 세트를 다루게 된다. 그러나 데이터가 클수록 처리 속도가 느려지고, 분석의 복잡성이 증가할 수 있다.
Continue reading
손실 함수(Loss Function)는 머신 러닝 모델이 학습하는 과정에서 예측의 정확도를 평가하는 중요한 도구이다. 손실 함수의 결과는 모델의 성능을 측정하고, 이를
Continue reading
지난 포스트에서는 좋은 알고리즘이 갖춰야 할 주요 특징들을 살펴보았다. 이번에는 머신 러닝과 인공지능의 핵심 개념 중 하나인 손실 함수(Loss Function)에
Continue reading
머신러닝 모델을 구축할 때, 사용되는 데이터의 유형은 매우 다양할 수 있다. 이 중 하나의 접근법이 바로 “Mixed Data Learning”이다. 이
Continue reading
Jupyter Notebook과 Jupyter Lab은 데이터 사이언티스트와 개발자에게 필수적인 도구이다.이들 환경에서는 단축키를 사용하여 생산성을 더욱 극대화할 수 있으므로, 단축키를 정리하여 공유
Continue reading
현대의 인공지능(AI) 모델은 정확한 예측과 성능을 위해 대용량의 빅 데이터로 학습하는 것이 중요하다. 그러나 대용량 데이터를 불러오고 전처리하는 데는 상당한
Continue reading